Embracing AIOps for Incident Management
The tech world has been affected a lot lately with the help of AIOps. Automation was taken a step further with the help of Artificial Intelligence which provides teams with much faster root-cause analysis. One of the areas that benefit mostly from the adoption of AIOps is Incident Management.
The method of problem management’s main objective is to stop recurring problems. However, it is a time-consuming task to pick out key issues from thousands of examples. The implementation of AIOps helps teams have better collaboration and be more organized while allowing them to focus on improving user experience.
In this article, we are going to talk about how by going through detection and identification AIOps can improve Incident Management.
The Advantages of Using AIOps for Incident Management in IT Operations
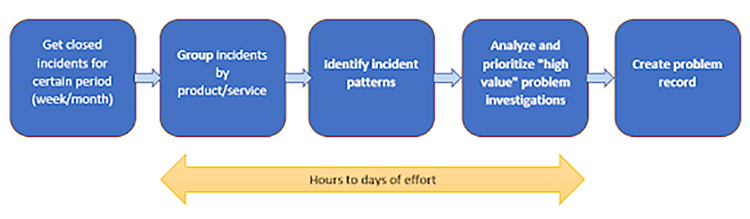
It is a responsibility when a problem occurs, to sort through all of the noise and data to identify a root cause.SREs (Site Reliability Engineers) and DevOps team work together. Once they detect and identify an incident, they must correctly categorize and prioritize it before deciding which teams and people to alert and involve.
It is a difficult and time-consuming task for any human to communicate with and analyze large amounts of diverse data points. Furthermore, the complexity of data sources increases along with the complexity of services and infrastructures. Since incident management can quickly become too much for a single team to handle, expanding the team was frequently the obvious solution. However, without relying solely on team members, artificial intelligence can assist teams in efficiently monitoring and comprehending all of their data.
People refer to Artificial Intelligence for IT Operations as AIOps. Additionally, AIOps can offer DevOps teams AI-backed insights and intelligence. This is achieved by using data science and artificial intelligence to analyze all of the data provided by your IT operations and DevOps tools. Automated incident management procedures, such as achieving faster root cause analysis.
AIOps automatically identifies incidents through data analysis.
- Incident prioritization: AIOps can also prioritize incidents automatically.
- Incident assignment: The system will determine which team members, if any, need to participate in responding to an event. In some circumstances, AIOps can use prior knowledge to autonomously resolve situations.
- Incident response: Incident response times are dramatically improved with AIOps automation, allowing team members to focus more on customer satisfaction and user experience.
AIOps allows teams to proactively detect and respond to incidents in real time while applying machine learning (ML) to predict and prevent future or related problems from occurring.
Top AIOps Tools for Incident Management
AI technologies power some amazing tools that assist in Incident Management. Through these tools, the system learns about itself more quickly and effectively when creating smarter algorithms.
Runbook Automation (Rundeck)
A runbook is a manual for carrying out typical actions inside a certain workflow. Automating runbooks enables the automatic execution of stages and checks, yielding faster and more dependable results.
Github (Puppet and Evolven)
You may find excellent open-source AIOps technologies to incorporate into your infrastructure by searching the Github community. The open-source management and deployment tool Puppet Automation allows for the automation of system administration tasks. Evolven is a fantastic AIOps tool for managing and detecting incidents.
PagerDuty Event Intelligence
TPagerDuty Event Intelligence, a potent AIOps tool, minimizes noise and equips DevOps teams with essential knowledge for effective issue resolution. Event Intelligence groups alert dynamically based on content, timing, previous groupings, and custom thresholds chosen by your team. Smart noise reduction efficiently mutes alerts that don’t require a response.
The goal of Incident Detection
The goal of incident detection for event data is to identify, for each unique Detection, what is the underlying cause and the best fix action. Identifying the likely underlying causes and suggested fix actions in the evolution of the Detection is crucial. This process can span several hours, but the sooner we do it, the more efficiently we can resolve the issue.
The steps to incident detection are as follows:
- identify a training period with historical events already grouped into detections,
- calculate event type embeddings for each detection,
- apply secondary clustering on the detections to ‘jump start’ the detection type labeling process,
- curate the generated detection type labels,
- enrich selected/important detection types with initial metadata,
- connect to incident management workflow for in-process supervision.
The final step is to connect Grok to existing Incident Management workflows so that Grok can continue to learn. When Grok identifies a detection as a specific type, it creates an Incident in the external Incident Management system. If the label remains unchanged after creating the incident, however, Grok will consider the detection correctly labeled and include it in the subsequent round of supervised training. Conversely, if the label is updated to a different incident type, Grok will consider that detection as labeled with the new incident type for the subsequent round of supervised training.
Conclusion
AI/ML technologies can help IT problem managers identify impactful problems quickly, reduce manual efforts and isolate recurring problems that impact business and operational efficiency.
If you enjoyed this insight, don’t miss out on our deep dive into The Power of AIOps: Unraveling Observability Overload. Check it out now for a comprehensive understanding!