Supervised Learning as it relates to ITOps
Machines may be trained using training datasets and then output can be predicted using supervised machine learning. As a result, we must divide our dataset into two sections: a training dataset and a test dataset. The training dataset is used to train our network, while the test dataset is used to test our model’s accuracy or to forecast fresh data.
Supervised learning is the process of giving accurate input data and output data to the machine learning model. The majority of real-world machine learning relies on supervised learning, and this method is used when there are input variables (x) and an output variable (Y), and the objective of the function generated by these two variables is to approximate the mapping function at the point where you can predict the output variable (Y) for new input data (x) when it is given.
Y= f(x)
Because an algorithm learning from the training dataset can be compared to a teacher supervising the learning process, it is known as supervised learning. The algorithm iteratively produces predictions on the training data and is corrected by the teacher because we are aware of the right answers. When the algorithm performs to an acceptable standard, learning ceases.
Supervised learning problems can be further grouped into regression and classification problems.
Classification: A classification problem is when the output variable is a category, such as “red” or “green” or “disease” and “no disease”. Listed below are some popular algorithms under classification algorithms:
- Decision Trees
- Random Forest
- Logistic Regression
- Support vector Machines
Regression: A regression problem is when the output variable is a real value, such as “dollars” or “weight”. Below are some popular Regression algorithms which come under supervised learning:
Linear Regression
- Regression Trees
- Non-Linear Regression
- Bayesian Linear Regression
- Polynomial Regression
Workings of Supervised Learning
Through Supervised learning, models are trained using a labelled dataset, where the model is trained to learn about different types of data. The model is tested using test data (which is a subset of the training set) after the training process is done, and it then predicts the output.
The way that Supervised learning works can be easily understood by the example below:
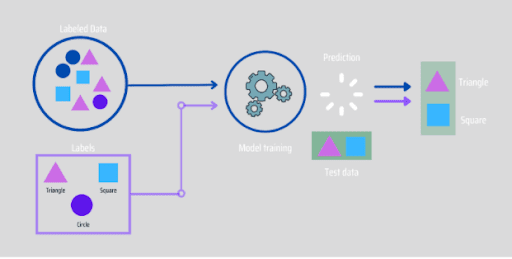
For example, if we have a dataset of different types of colours which includes square, rectangle, triangle, and Polygon. Now the first step is that we need to train the model for each shape.
- If the given shape has four sides, and all the sides are equal, then it will be labelled as a Square.
- If the given shape has three sides, then it will be labelled as a triangle.
- If the given shape has six equal sides then it will be labelled as hexagon.
Now, after training, we test our model using the test set, and the task of the model is to identify the shape.
The machine has already been trained on a variety of shapes, so when it encounters a new shape, it classifies it based on a number of sides and predicts the outcome.
The following are the steps in which Supervised Learning takes place:
- First is defining the type of training dataset;
- Collect and gather the labelled training data;
- Split the training dataset into training dataset, test dataset, and validation dataset;
- Determine the input attributes of the training dataset, which should have enough knowledge so that the model can accurately predict the outcome;
- Decide the suitable algorithm for the model, such as support vector machine, decision tree, etc;
- Execute the algorithm on the training dataset. Sometimes we need validation sets as the control parameters, which are the subset of training datasets;
- Evaluate the accuracy of the model by providing the test set. If the model predicts the correct output, which means our model is accurate;
Applications of Supervised Learning?
A lot of daily processes that we go through are based on supervised machine learning algorithms. Some of them are listed below:
- Text categorization;
- Face Detection;
- Signature recognition;
- Sales Forecasting;
- Supply and demand analysis;
- Personalizing reviews for goods;
- Weather forecasting;
- Predicting housing prices based on the prevailing market price;
- Stock price predictions.
How does the new generation of AI and ML address shortcomings in ITOPs
The creators of Grok approached this issue from a fundamentally new and inventive perspective. In order to properly sort through all monitoring noise and identify true problems, their causes, and to prioritize them for response by the IT team, they have created and built a revolutionary new system using a meta-cognitive model (MCM).
The Grok creators understood that for any event-processing design approach to be effective, AI and Machine Learning have to be the core components and not only ancillary ones. The new method was unable to rely on a strict rules-based approach taken from older event management systems or even on some first-generation AIOps.
Because the IT environment was so dynamic and because each individual environment was so distinct from the others, these AIOps 1.0 systems were unable to effectively resolve and productively interpret monitoring noise. These problems showed that AIOps inventors needed to stay away from the trap of depending on codebooks, recipes, and other formulations of embedded rules. These solutions have the same limitations as prior attempts at applied AI, such as expert systems. For incident classification, root cause investigation, and prediction, The Grok founders concentrated on using an MCM that incorporated AI and machine learning.

End-users wanted an AI/ML platform that helped them with multiple use cases across the entire ITOps domain, not just a single use case, and Grok delivered. By using a focused MCM purpose-built for this entire domain, Grok self-learns and self-updates as it experiences new information and feedback from humans.
With Grok and its ML early warning capabilities on the organization’s IT team, the team can become lean and nimble, efficient and pro-active, and IT systems in their care can be optimized to perform as the system’s design engineers intended.
Read more here: About New Generation of AI and ML to Address Shortcomings