PART 1: AIOps 2.0 – The Evolution of Event Correlation
The problem of event correlation has been felt deeply since the dawn of large-scale distributed computing. Throughout the last 30 years, as networks evolved, armies of technical support personnel were required to keep an eye on event screens and respond to pages on their mobile devices relating to potential issues. The number of personnel required to watch these screens and be “on call” is greatly reduced with better event correlation. In terms of an organization’s strategy for correlating events before visualization and management by first-line support workers, there are three levels of maturity:
- Rules-based
- Static Correlation with Algorithmic Support
- Dynamic AI-based Correlation.
An association rule is a well-known strategy for exploring potential patterns, correlations, and relationships in a variety of datasets and other data sources. Measurement/context and selection are two of the most difficult aspects of developing association rules. How do we determine the degree to which our goal data is related? How do we choose the groups/clusters that an algorithm or experience has identified? We normally employ data mining approaches when dealing with large datasets, and in this situation, the association rules tend to provide us with a large number of rules from which to build a good model.
Exploring Association Rules and Market Basket Analysis
As a customer, were you happy to be recommended products in e-commerce stores that you didn’t even know you may need or like? If yes, there’s a whole “rule” behind it that we’d be happy to briefly explain. This rule known as “Market Basket Analysis” is a famous example of this type of data mining technology in practice (MBA). When we talk about association rules, we usually refer to MBA. MBA was one of the first areas where association mining was used. We tend to detect correlations between components that occur together more frequently than we would expect if we randomly sampled all the options.
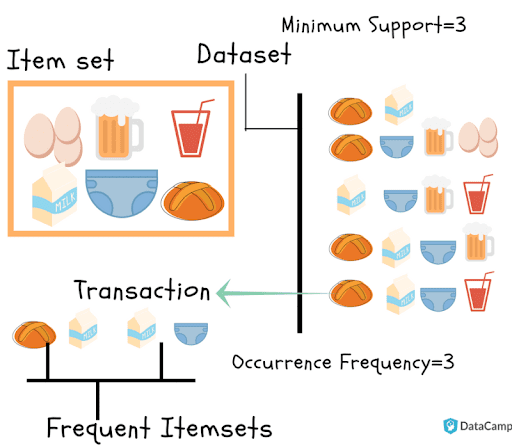

An example of Association Rules:
Assume there are 100 customers
- 10 of them bought milk, 8 bought butter and 6 bought both of them.
- bought milk => bought butter
- support = P(Milk & Butter) = 6/100 = 0.06
- confidence = support/P(Butter) = 0.06/0.08 = 0.75
- lift = confidence/P(Milk) = 0.75/0.10 = 7.5
The task of developing effective association rules in an IT setting is generally referred to as event correlation. Organizations at various stages of AIOPS maturity can reduce costs and improve the effectiveness of their IT organization by investing in event correlation.
PART 2: AIOps 2.0 – The Evolution of Event Correlation
Rule-based correlation
Rule-based correlation uses traditional correlation logic to analyze information collected in real-time. This correlation takes all logs, events, and network flows that are correlated together along with contextual information such as identity, roles, vulnerabilities, and more—to detect patterns indicative of a larger threat. There are mainly two types of rules: network topology-based rules and service model-based rules.
Figure 1.1: Simple Topology Example
Figure 1.2: Simple Business Service Model Template
For the network topology-based rules, firstly, we must build an inventory of all network devices and subcomponents. Secondly, we must draw edges between each component connected to the network or some layer of the OSI protocol stack. Once those edges are defined, we can build the rules to group events if their originating devices, for instance, are within 2 hops of each other. Rules specific to particular types of devices and parts of the network have to be developed and managed over time (Fournier-Viger et al., 2021). Certainly, there are pros and cons to using this rule. Unfortunately for us, the cons of this particular rule outweigh the pros.
Pros:
- Easy to impose correlation logic if the behavior of the system is deterministic
- For incidents whose root cause is a network failure, a rule based on inference applied to the topology (simple connectivity inference) of the network will often suffice for accurate grouping of the events related to that root failure.
Cons:
- Difficult to accurately inventory ever-evolving, large networks- leading to reduced efficacy and increased skepticism. A statically defined Configuration Management Database (CMDB) has a high rate of entropy.
- Difficult to map topological relationships across network devices. Network discovery tools can help with this (as well as the entropy problem) but they are very difficult and expensive to implement across large complex networks and the complex configurations required are very brittle over time as the network evolves. This leads to high maintenance costs and usually a reduction of scope that minimizes the efficacy of the CMDB.
- Limited generalization of rules leads to many static rules over time. For example, the causal relationship between 2 directly connected network devices (an app server and a database server) might make sense in that if a node-down event comes from both the server and the database, it probably makes sense to group them. Rules that effectively group more than just directly connected devices are difficult to construct, leading to a limitation in the amount of event compression that can be realized.
- High implementation costs to implement the discovery tools and the CMDB
- High development costs to build and deploy static correlation rules
- High maintenance costs to effectively maintain the CMDB, the topology, and the static correlation rules.
- Cost and complexity can lead to minimally effective deployments even after large time and software expenses
Figure 1.3: Simple Topology-Based Inference Rules
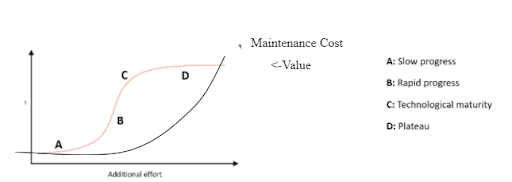
Figure 1.4: Diminishing Value of Rules-Based Correlation as New Rules Are Developed
On the other hand, service model-based rules require that services be defined in a way that event metadata can be associated with a particular service. This metadata may be node information or other logical components of the service. Similar to network topology, the service models must map common edges across these logical components. Similarly to topology-based rules, the cons of this rule also outweigh the pros.
Pros
- Easy to impose correlation logic if the behavior of the system is deterministic
- The rule development can be prioritized such that the most important services are defined first
Cons
- Difficult to accurately define services across a large and complex business in a way that makes it reasonable to map events to those components of the model.
- Difficult to accurately map service relationships across network devices.
- Limited generalization of rules leads to many static rules over time. Service models are typically ‘all-or-nothing’ such that events that match a service model are grouped, and events that don’t are. But services often share the same infrastructure components at different layers of the network so disambiguating concurrent incidents is difficult.
- High implementation costs to work with each business unit to define service models
- Long deployment times
- High maintenance costs to effectively maintain the service relationships- specialized skills are required but business unit SMEs might be reluctant to take on the work and training required.
- Cost and complexity can lead to minimally effective deployments even after large time and software expenses
- Cost and complexity can lead to minimal compression of the event stream, where only the most important services are effectively defined.
In general, rules-based correlation can provide only limited compression of the event stream, but with sufficient development time, can provide for moderately accurate correlation.
PART 3: AIOps 2.0 – The Evolution of Event Correlation
Level 2A: Static Event Correlation with Algorithmic Recommendations
AIOps 2.0 Event Correlation, specifically in the context of Static Event Correlation with Algorithmic Recommendations, is the process of investigating historic logs and events to analyze the failure or breach after an incident. By applying historical data to a statistical correlation model, we can analyze log data and identify complex patterns from past events. This can also help us discover threats that may have compromised your network’s security, or give you information about an ongoing attack (ManageEngine, 2021).
This type of correlation involves obtaining a batch of operational data from event and log sources and performing a statistical analysis or statistical learning task against the batch of data. This is typically performed with a classical clustering algorithm like K-Means or Hierarchical clustering. As an output of the clustering algorithm, all event types are assigned to a static prototype group. These groups are analyzed by human operators and groups that are determined to be understandable and actionable are deployed in production as a static rule. For example, if event type 1 and event type 2 belong to the same prototype group then every time they occur in a time window they are grouped.
Pros
- Potential for significant compression based on an initial application of clustering across all the output prototypes
Cons
- “Once a cluster in the AIOps 2.0 Event Correlation strategy is ‘approved’, it becomes a static entity that will only change if a human operator decides to modify it, either based on tribal knowledge or further statistical analysis. Rules are built on top of these static clusters- e.g. notification rules, assignment rules, escalation rules, etc.
- Maintenance of the clusters and the upstream rules grows exponentially as the number of clusters grows.
- Any change in the underlying fabric of the network/services requires additional statistical analysis and merging of new knowledge into the existing cluster prototype ‘library’.
- Can’t capture ‘fuzzy’ boundaries across clusters. An event type either belongs to a cluster or it doesn’t, but the reality is more subtle.
PART 4: AIOps 2.0 – The Evolution of Event Correlation
Level 2B. Static Correlation with some statistical enhancements (SCSE)
This type of correlation involves defining a set of codebooks or recipes that specify a predetermined relationship between event types. Once the relationship is established statistical learning techniques can be applied to reduce intra-group noise by filtering out events from the group if the events do not meet a specified threshold of information gain or entropy. In other words, if the particular event occurs very often but meets the code-book specification for membership, it may be filtered out because it doesn’t provide any useful additional information.
Pros
- Potential for significant compression once a large number of code books are developed
Cons
- Cookbooks are typically defined using mostly tribal knowledge, with some statistical tools to provide backup or guideposts
- Once a cookbook is defined it becomes a static entity that will only change if a human operator decides to modify it. Rules are built on top of these statically generated clusters- e.g. notification rules, assignment rules, escalation rules, etc.
- Maintenance of the cookbooks and the upstream rules grows exponentially as the number of cookbooks grows.
- Any change in the underlying fabric of the network/services requires additional analysis and merging of new knowledge into the existing cookbook ‘library’.
- Can’t capture ‘fuzzy’ boundaries across clusters. An event type either belongs to a cluster or it doesn’t, but the reality is more subtle. Applying statistical tests (entropy) to filter membership helps a little, but doesn’t allow for much variability in the dynamics of the network
Dynamic and automated correlation groups all related events together in real time.
This type of correlation strategy argues that network dynamics are too complex to model effectively with a rules-centric strategy. Therefore, the goal of DAC correlation is to base the bulk of decision-making (when determining if 2 events should be grouped) in the hands of a learning algorithm or series of learning algorithms. In this way, the models learn over time without human engagement but can benefit from human feedback.
One way to think about this strategy in contradistinction to a Level 2 strategy is that of the difference between a mechanical automaton from the 1700s, designed to operate in precise combinations of movements, versus the Boston Dynamics robotic dog that can learn new behaviors, such as to walk, from scratch. If the environment changes, i.e. we add a step to its path, a rule-based dog will no longer function. But a learning dog will fail and probably fail again, but eventually learn to function in the new environment.
With this model, a representation of all observed phenomena in the environment is stored and continuously updated. Classically this is performed in a distance matrix that stores the computed similarity or distance of each pairwise object observed (event types). The actual decision on whether to group 2 events is based on (1) whether or not the two events are being observed in the same time window and (2) the posterior probability of such concordant observation.
Pros
- Significant and speedy compression of event streams
- Very little work is required to start
- No prior knowledge of network or service connectivity is required to see substantial benefits
- The system learns dynamically, and automatically with each new observation
- Humans can provide feedback directly into the system to interactively modify behavior over time
- Heuristics (rules) can be added to supplement and enhance the AI-centric output, without negatively impacting the underlying mechanics
- Topology-based; service based
- Tribal knowledge
Cons
- Organizations have to be trained somewhat on machine learning concepts to understand the underlying mechanics.